![]()
How to import OCR pre-annotations
In this tutorial we will see how to import OCR pre-annotations in Kili using Google vision API.
Pre-annotating your data with OCR will save you a lot of time when annotating transcriptions in Kili.
The data that we use comes from The Street View Text Dataset.
Loading an image from The Street View Dataset in Kili
Follow this link to get the image for this tutorial:
We will use the Google Vision API to perform Optical Character Recognition on the different inscriptions in this image.
To use the google API, we need to install some packages:
!pip install google-cloud google-cloud-vision Pillow kili google-cloud-storage wget
import os
import io
import json
from google.cloud import vision
from google.oauth2 import service_account
from kili.client import Kili
from PIL import Image
import wget
import getpass
We can now create the project ontology (json interface).
For a transcription task on images, the ontology is a classification job with nested transcriptions for each category:
json_interface = {
"jobs": {
"JOB_0": { # this job is for annotating the bounding boxes
"mlTask": "OBJECT_DETECTION",
"tools": ["rectangle"],
"instruction": "Categories",
"required": 1,
"isChild": False,
"content": {
"categories": {
"STORE_INFORMATIONS": {"name": "Store informations", "children": ["JOB_1"]},
"PRODUCTS": {"name": "Products", "children": ["JOB_2"]},
},
"input": "radio",
},
},
"JOB_1": {
"mlTask": "TRANSCRIPTION",
"instruction": "Transcription of store informations",
"required": 1,
"isChild": True,
},
"JOB_2": {
"mlTask": "TRANSCRIPTION",
"instruction": "Transcription of products",
"required": 1,
"isChild": True,
},
}
}
Let's initialize the Kili client and create our project:
if "KILI_API_KEY" not in os.environ:
KILI_API_KEY = getpass.getpass("Please enter your API key: ")
else:
KILI_API_KEY = os.environ["KILI_API_KEY"]
kili = Kili(api_key=KILI_API_KEY)
# Create an OCR project
project = kili.create_project(
description="OCR street view",
input_type="IMAGE",
json_interface=json_interface,
title="Street text annotation",
)
project_id = project["id"]
Creating OCR annotations using Google Vision API
We will now see how to perform OCR preannotation on our image using Google Vision API.
First you will need to create an account on Google Cloud:
- create a project (or use an existing one)
- then go to the Cloud Vision API page
- activate the API for your project
Now that the API is activated we will need to get a secret key in order to call the API later in our project:
- go to API and services page
- and create a service account with authorization to use the vision API
On the service account details page:
- click on add a key
- download the key using json format
- place the key in your environment variables or in a file
google_key_str = os.getenv("KILI_API_CLOUD_VISION")
if not google_key_str:
path_to_json_key = "./google_cloud_key.json"
with open(path_to_json_key) as file:
google_key_str = file.read()
GOOGLE_KEY = json.loads(google_key_str)
assert GOOGLE_KEY
We can now start adding OCR pre-annotations to the asset metadata:
def implicit():
from google.cloud import storage
# If you don't specify credentials when constructing the client, the
# client library will look for credentials in the environment.
storage_client = storage.Client()
# Make an authenticated API request
buckets = list(storage_client.list_buckets())
print(buckets)
def detect_text(path):
"""Detects text in the file."""
credentials = service_account.Credentials.from_service_account_info(GOOGLE_KEY)
client = vision.ImageAnnotatorClient(credentials=credentials)
with io.open(path, "rb") as image_file:
content = image_file.read()
response = client.text_detection({"content": content})
texts = response._pb.text_annotations
text_annotations = []
for text in texts:
vertices = [{"x": vertex.x, "y": vertex.y} for vertex in text.bounding_poly.vertices]
tmp = {
"description": text.description,
"boundingPoly": {
"vertices": vertices,
},
}
text_annotations.append(tmp)
if response.error.message:
raise Exception(
"{}\nFor more info on error messages, check: "
"https://cloud.google.com/apis/design/errors".format(response.error.message)
)
return text_annotations
PATH_TO_IMG = wget.download(
"https://raw.githubusercontent.com/kili-technology/kili-python-sdk/master/recipes/img/store_front.jpeg"
)
text_annotations = detect_text(PATH_TO_IMG)
assert len(text_annotations) > 0
print(f"Found {len(text_annotations)} boxes of text.")
print(text_annotations[0])
Found 22 boxes of text.
{'description': "CD\nITALIAN $1\nESPRESSO Shot\nplus tax\nFINE ITALIAN\nIMPORTS & DELI\nJIM\nIMMY'S FRESH MEATS\nSAUSAGES\nFOOD STORE\nIX", 'boundingPoly': {'vertices': [{'x': 24, 'y': 6}, {'x': 1668, 'y': 6}, {'x': 1668, 'y': 553}, {'x': 24, 'y': 553}]}}
im = Image.open(PATH_TO_IMG)
IMG_WIDTH, IMG_HEIGHT = im.size
print(im.size)
(1680, 1050)
We now need to convert the OCR predictions to the Kili asset metadata format:
full_text_annotations = {
"fullTextAnnotation": {
"pages": [{"height": IMG_HEIGHT, "width": IMG_WIDTH}],
},
"textAnnotations": text_annotations,
}
We follow the Google Vision API AnnotateImageResponse format. So in the end, the OCR data to insert into Kili as a JSON metadata contains:
- Full text annotation. A list of pages in the document with their respective heights and widths.
- A list of text annotations with:
- text content
- bounding box coordinates.
{
"fullTextAnnotation": { "pages": [{ "height": 914, "width": 813 }] },
"textAnnotations": [
{
"description": "7SB75",
"boundingPoly": {
"vertices": [
{ "x": 536, "y": 259 },
{ "x": 529, "y": 514 },
{ "x": 449, "y": 512 },
{ "x": 456, "y": 257 }
]
}
},
{
"description": "09TGG",
"boundingPoly": {
"vertices": [
{ "x": 436, "y": 256 },
{ "x": 435, "y": 515 },
{ "x": 360, "y": 515 },
{ "x": 361, "y": 256 }
]
}
}
]
}
Let's upload the asset with its pre-annotations to Kili:
external_id = "store"
content = PATH_TO_IMG
kili.append_many_to_dataset(
project_id=project_id,
content_array=[content],
external_id_array=[external_id],
json_metadata_array=[full_text_annotations],
)
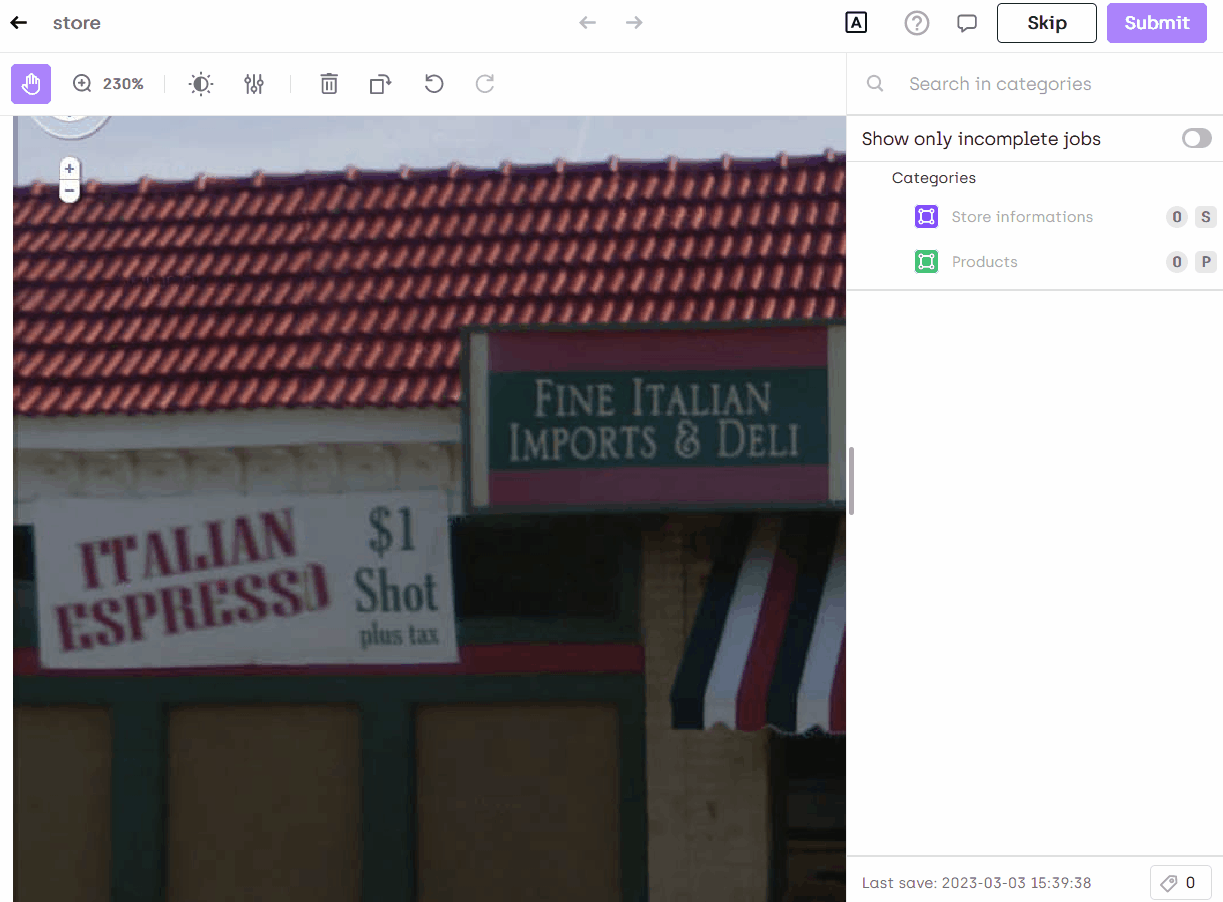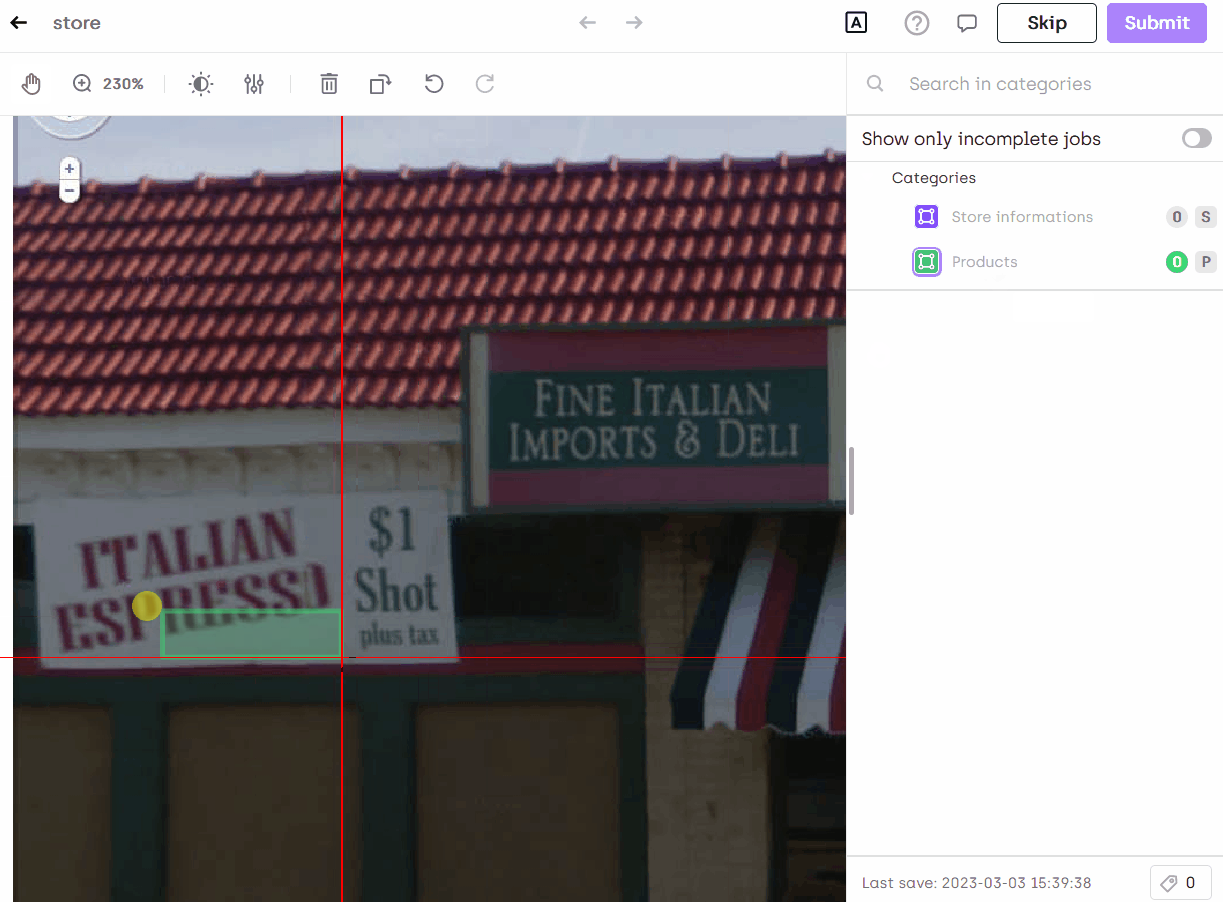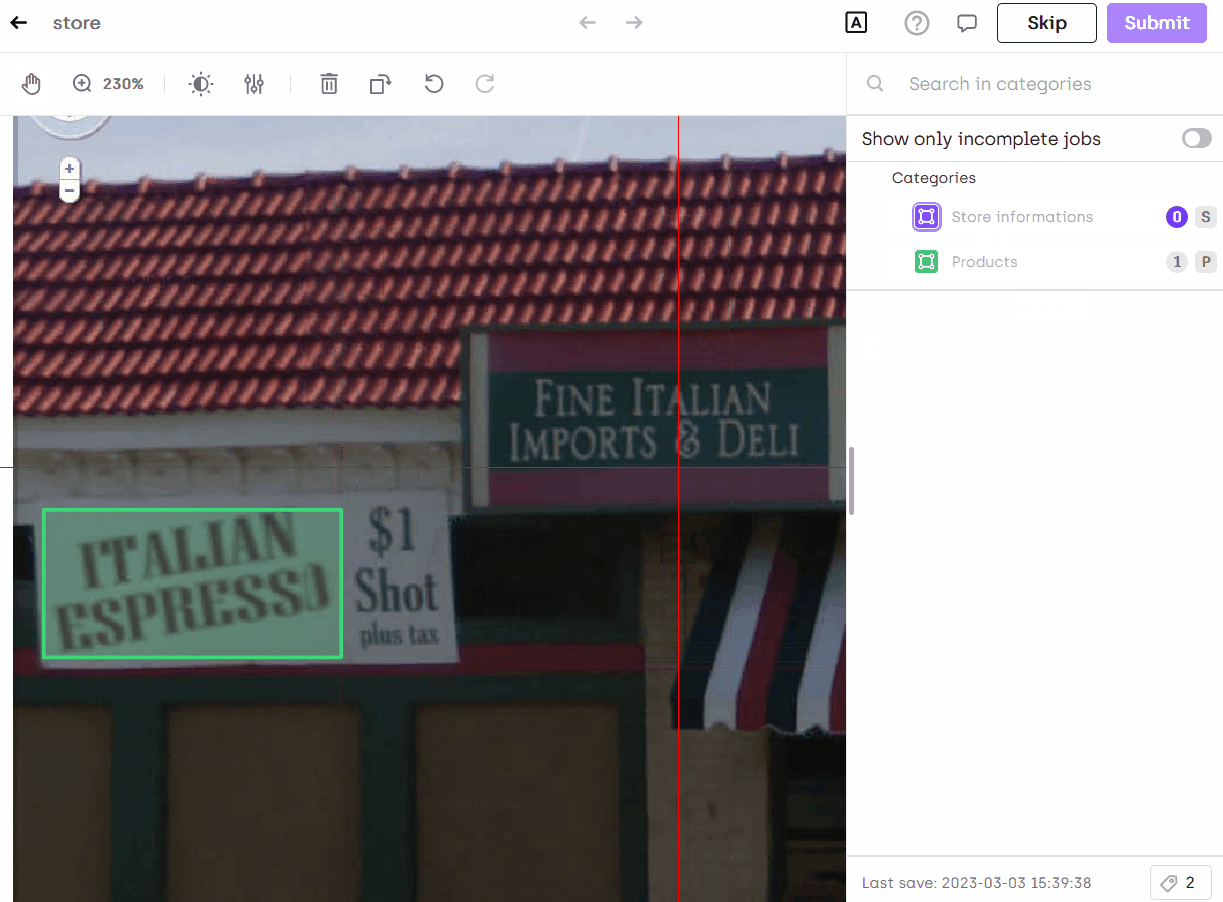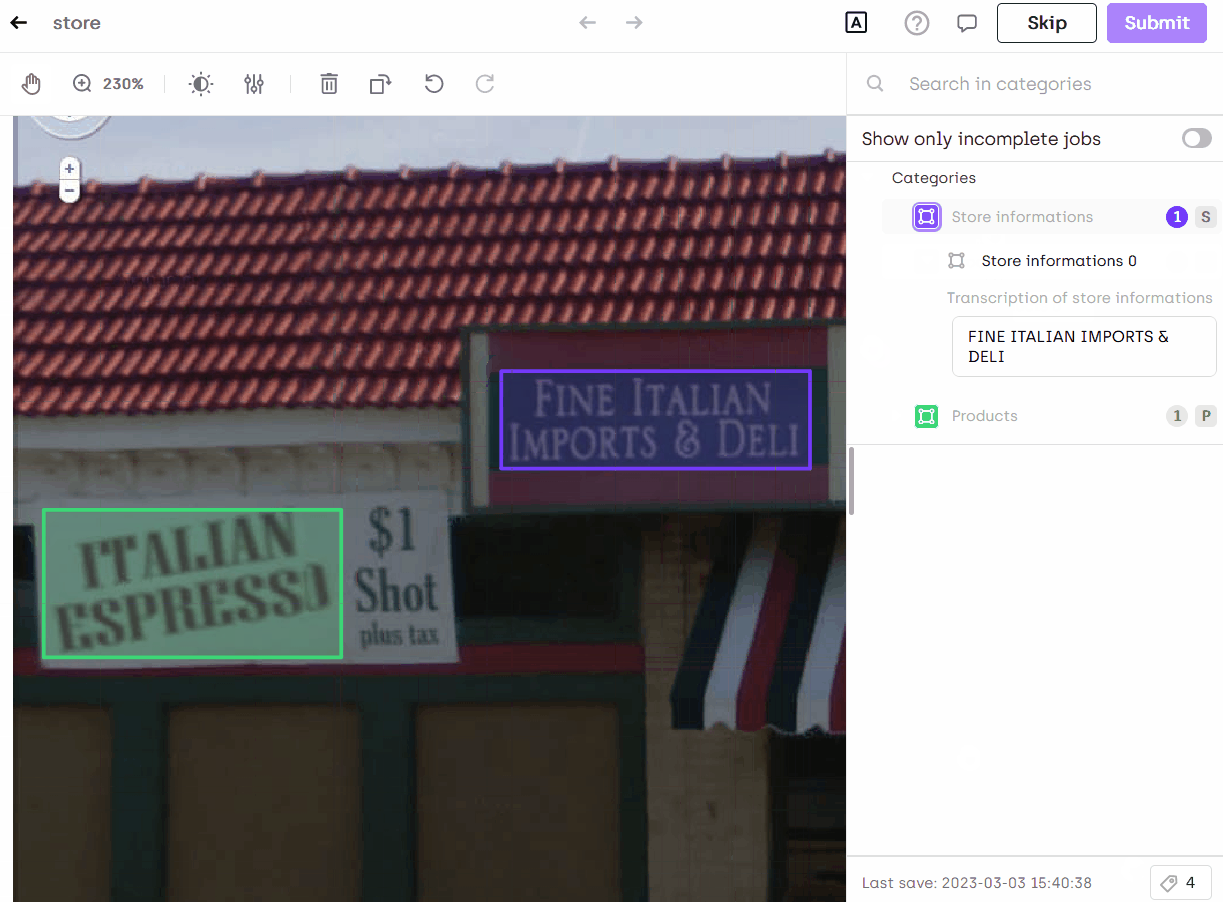
Annotate in Kili
You can now annotate your images and you will see the text automatically extracted:
Congrats! 👏
Pre-annotating your assets can save you a significant amount of time and improve the accuracy of your labeling ⏳🎯.
Cleanup
To clean up, we simply need to remove the project that we created:
kili.delete_project(project_id)